How I Perceive It: Human Memory-Augmented Analogical Reasoning for Machine Visual Interpretation
BibTeX
@inproceedings{10.1145/3757369.3767595,
author = {Cai, Zhuodi},
title = {How I Perceive It: Human Memory-Augmented Analogical Reasoning for Machine Visual Interpretation},
year = {2025},
isbn = {9798400721298},
publisher = {Association for Computing Machinery},
address = {New York, NY, USA},
url = {https://doi.org/10.1145/3757369.3767595},
doi = {10.1145/3757369.3767595},
abstract = {How I Perceive It augments machine visual interpretation with human memory, shifting from superficial seeing to deep perceiving. Although today’s vision language models (VLMs) can generate image captions with a degree of subjectivity, they still struggle to explain the underlying reasons or experiential basis for such subjectivity. Machines can see, but they do not perceive as humans do, who link perception with prior experience and memory. To bridge this gap, this paper introduces a visual interpretation system that integrates individual memory into machine perception, founded on structure-mapping theory. By merging what the machine sees with what the individual remembers, the system produces individualized interpretations that uncover more insightful meanings among visual elements that are not immediately visible on the surface.},
booktitle = {Proceedings of the SIGGRAPH Asia 2025 Art Papers},
articleno = {12},
numpages = {8},
keywords = {Human-AI Collaboration, Vision-Language Models, VLMs, Cognitive AI, Explainable AI, Visual Interpretation, Memory, Analogical Reasoning},
location = {},
series = {SA Art Papers '25}
}
| Category | Duration | Tool / Material |
|---|---|---|
| ML/AI Application; Art | 2025 @ University of Washington | Python; JavaScript |
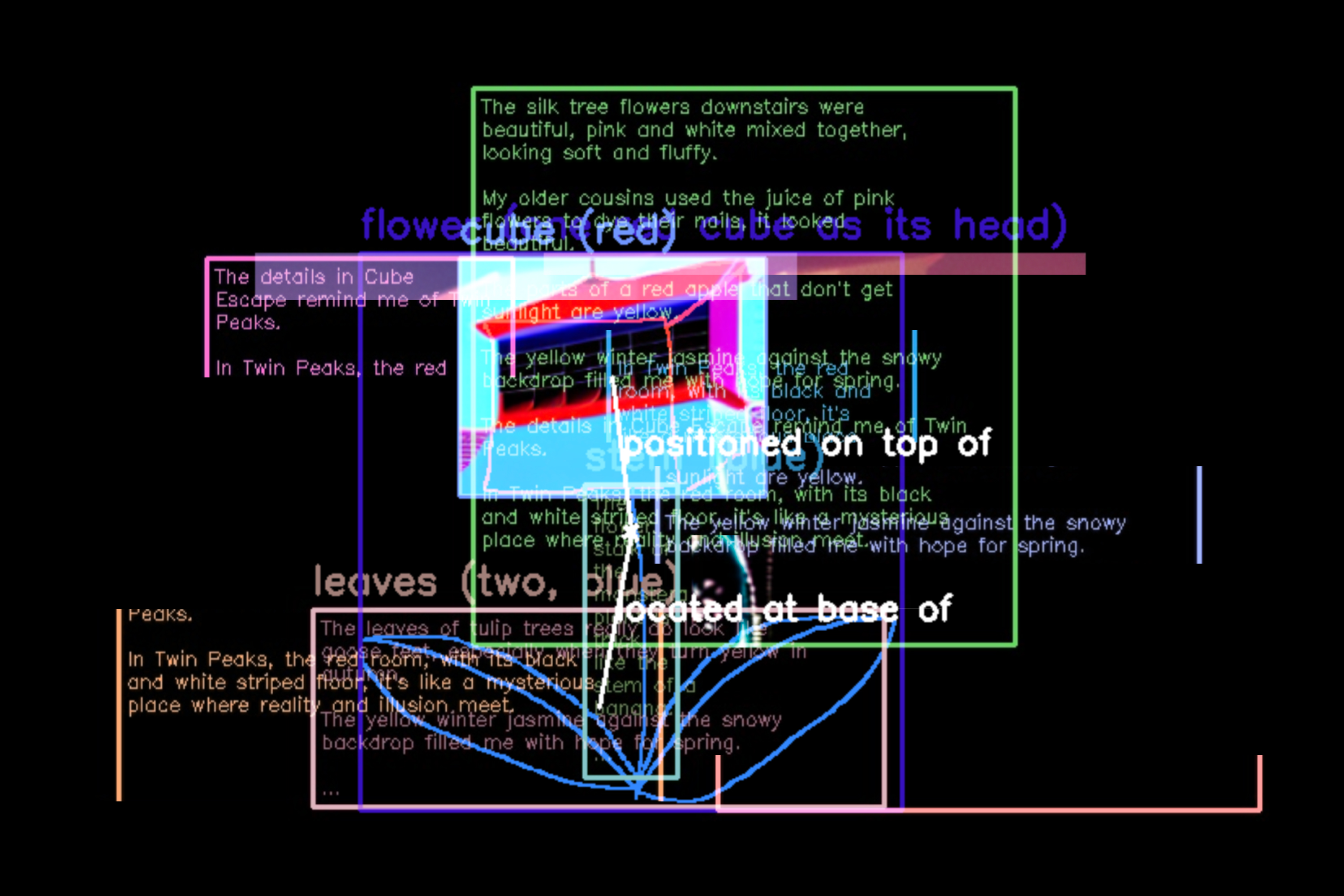 How I Perceive It augments machine visual interpretation with human memory, shifting from superficial seeing to
deep perceiving. Although today’s vision language models can generate image captions with a degree of subjectivity, they
still struggle to explain the experiential basis of such subjectivity. Machines can see, but they do not perceive as
humans do, who link perception with prior experience and memory. This work explores how individual memory may
participate in machine visual interpretation through analogical reasoning.
How I Perceive It augments machine visual interpretation with human memory, shifting from superficial seeing to
deep perceiving. Although today’s vision language models can generate image captions with a degree of subjectivity, they
still struggle to explain the experiential basis of such subjectivity. Machines can see, but they do not perceive as
humans do, who link perception with prior experience and memory. This work explores how individual memory may
participate in machine visual interpretation through analogical reasoning.
The system is implemented using multiple state-of-the-art vision-language and generative models. Applied in an
audiovisual art installation, these reinterpretations are expressed through memory-conditioned imagery, animated
collages, and synthesized sound. Recognized elements, retrieved memories, and AI-reimagined visuals are overlaid and
accompanied by glitch effects that reflect the instability and incompleteness of human recall. Narration in the artist’s
cloned voice further blurs the boundary between internal memory and external mediation, forming a continuous yet
unstable sense of self.
Like Funes, as described by Jorge Luis Borges in Funes the Memorious, a machine may remember too much to
abstract meaningfully. Meaning may emerge not from what could be remembered, but from what must be forgotten.
Through entanglement, human and machine jointly decide what to discard and what to preserve, thereby constructing
meaning.
Full details can be found in the proceedings of ACM SIGGRAPH Asia 2025 (How I Perceive It: Human Memory-Augmented
Analogical Reasoning for Machine Visual Interpretation, Article No. 12, pp. 1–8).